Variables, Number Systems, and I/O
Variables
Variables are what we store values in. A value can be anything from a primitive value, all the way up to an object instance. They’re declared like this:
// Creating an integer variable
int x = 5;
// Creating a String variable
String str = "I am a string";
// Instantiating a Scanner object and storing it in a variable
Scanner sinput = new Scanner(System.in);
// You can then call Scanner methods like so:
int a = sinput.nextInt();
Number systems
Two’s Complement
Useful links: source conversion tool
Two’s complement is the way in which computers represent integers. To get the two’s complement negative notation of an integer, you perform the following steps:
- Write out the number in binary
- Invert the digits
- Add one to the result
It is a given that if the leftmost bit is a 1, then this number is negative.
⚠ Important: If you are converting a positive integer to two’s complement form, then you simply do a basic conversion. When converting to binary, you only invert the bits if you have a negative number. Similarly, if you see the number 00011110, this is 30- you do not need to do the hokey-pokey inversion magic. If you are reading from a binary number, you can either read the basic decimal number OR the decimal from the signed 2’s complement. In which case, the number 11111101 would read 253 and -3 respectively.
For example, given 8 bits and the number -28:
Write out the binary form of +28
28 = 0 0 0 1 1 1 0 0
Invert the digits
0 0 0 1 1 1 0 0 => 1 1 1 0 0 0 1 1
Add 1
1 1 1 0 0 0 1 1
1 +
-----------------
1 1 1 0 0 1 0 0
Two’s Complement: Converting to decimal
It is therefore also possible to convert from Two’s Complement; take the number 0xFFFFFFFF as an example. This is the hex representation of 1111 1111 1111 1111 1111 1111 1111 1111.
At first glance, we can tell that this number is negative, as it has a leading (leftmost) bit set to 1.
If you want to see what this number is a negative of, then we follow a similar set of steps:
- Invert all the bits
- Add one
Therefore, inverting all the bits 0xFFFFFFFF results in 0000 0000 0000 0000 0000. Then, adding 1 leads to 0000 0000 0000 0001, which is the number 1. Therefore, the negative of 0xFFFFFFFF is 1, and hence the value is -1.
Java’s numeric data types
| Type | Bytes | Value in Decimal |
|---|---|---|
byte |
1 byte (8 bits) | -128 to +127 |
short |
2 bytes | -32768 to +32767 |
int |
4 bytes | -231 to +(231 - 1) |
long |
8 bytes | -263 to +(263 - 1) |
We’ve seen how two’s complement is used to represent integers. For decimal numbers, like float and double, we use floating point notation to store their values (IEEE-754).
A float is 32-bits and can represent numbers between -3.4e38 and 3.4e38 with 6 to 7 significant digits of accuracy.
A double is 64-bits and can be represent numbers between -1.7e308 and 1.7e308 with 14 to 15 significant digits of accuracy.
IEEE 754 notation for floating point numbers
Useful links: GeeksforGeeks (source) Conversion Tool
Before we begin, a brief reminder on fractional binary: 9.125 = 1001.001. We achieved this result with the following intuition:
| Binary place values | 23 | 22 | 21 | 20 | 2-1 | 2-2 | 2-3 |
|---|---|---|---|---|---|---|---|
| Binary bits | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| Decimal values | 8 | 0 | 0 | 1 | 0 | 0 | 0.125 |
The table is a little janky, but it hopefully gets the point across; you continue in descending powers of 2 as you go rightwards. Anything beyond 2^0 is followed by a decimal place, ..
Components of the IEEE 754 Floating Point Number
Before diving into the components, it’s much better to look at an example. Therefore, take the decimal number 43.625; this has binary representation 101011.101. However, we would represent this as 1.01011101 x 25.
In general the value of a floating point number is determined by
(-1)(Sign Bit) x 1.(Mantissa) x 2(Biased Exponent) - 127
There are three basic components which make up the IEEE 754 floating point number:
- The Sign Bit: this is a single bit where a
0represents a positive number, whilst a1represents a negative number. - The Biased Exponent: this is an eight bit exponent field which represents both positive and negative exponents. It is biased because it is a fixed positive value that is then subtracted by 127 to represent either a positive or negative exponent. For example, given the exponent bits 100001002 = 13210. We arrive at the index 25 because 2132-127 = 25.
- The Mantissa: this is a twenty-three bit field which makes up the numbers to right of the decimal point
.(as shown in the formula above). The most significant bit (the left most) is 1/21, then 1/22, and so on. In most cases, the value before the.is 1, however in some cases which we will explain in the special cases section below, it may be 0 (this is when it is renormalised).
With these components established, we can rewrite our previous example, 43.625, 1.01011101 x 25 in IEEE 754 notation:
| Sign (1 bit) | Exponent (8 bits) | Mantissa (23 bits) |
|---|---|---|
0 |
10000100 |
01011101000000000000000 |
Complete representation: 0 10000100 01011101000000000000000
IEEE 754 Double-precision Number
Luckily for our computers, there is also a specification for double-precision numbers; it basically uses the same components, except for the fact that there are more bits.
(-1)(Sign Bit) x 1.(Mantissa) x 2(Biased Exponent) - 1023
- Sign Bit. No change in bits.
- Mantissa. 52-bits
- Biased Exponent. 11-bits
Special values
IEEE 754 also has some special values you need to keep in mind:
When the exponent bits = 0000 0000
- If the fraction is
0, the value is0or-0. - Otherwise, renormalise the number with this form: (
-1)sign bit x0.(fraction)x 2-127
The exponent bits = 1111 1111
- If the fraction is
0, the value is+- infinity. - Otherwise, the value is
NaN, otherwise known as not a number.
Output
The main content I gleamed from this was to be familiar with the three Linux streams:
| Stream | Purpose | Example |
|---|---|---|
System.in |
Collect input | Scanner uses this stream to collect user input |
System.out |
Send normal output | Your typical System.out.println() will output to this stream |
System.err |
Send output when there is an error | Some IDE’s such as Eclipse will output to this stream to highlight text in a different colour |
Casting
Generally speaking, this is the process of changing the data type of one piece of data from one type to another. You need to be familiar with the different types (pun not intended) of casting:
| Implicit casting | Explicit casting | |
|---|---|---|
| Definition | No loss of precision | Possible loss of precision |
| Example | float pi = 3.141f; double big_pi = pi; |
float pi = 3.141f; int less_pi = pi; |
The compiler will ‘let you know’ (otherwise known as screaming) if you attempt an explicit cast. However, if this is intentional you can do it like this.
// lets say you want to cast a variable from a float to an int
float pi = 3.144;
int more_pi = (int) pi; // essentially tells the compiler not to worry
Lazy and strict evaluation
You will be familiar with both &/&& and |/||; if you use either of these, your code will still compile correctly. However, one is strict whilst the other is lazy. If you need a quick way to remember this, a SINGLE CHARACTER means STRICT evaluation.
The only difference between a strict and a lazy evaluation is how many of the operands are computed; this means that if you are expecting something to happen on the RHS of a comparison, only a strict evaluation will execute the LHs as well as the RHS. In essence, a lazy comparison will only execute both operands if needed.
int a = 5;
// Lazy AND example; the LHS is false, so the overall statement is false. The RHS is not executed, and a = 5.
if (false && (a++ == 5)) {}
// Strict AND example; the LHS is false, but the RHS is still executed. a = 6 after this, even though the result is false.
if (false & (a++ == 5)) {}
// Therefore, a lazy OR operator will not execute the RHS if the LHS is true.
Pre- and Post-increment
There are two ways to increment a numerical variable using the ++ operation:
Prefix ++var |
Postfix var++ |
|---|---|
| The value is incremented first, and then returned. | The value is returned first, and then it is incremented |
I’ve found that a useful way to remember this is to think of where the ++ is; in the prefix case, the ++ precedes the variable name. Therefore, you can think of the return always happening when you reach the var. Hence, prefix ++var incremements and then returns, whilst postfix var++ returns and then increments.
Operator precedence (BIDMAS on steroids)
The Java creators realised that they too wanted to implement operator precedence. It follows this order:
| P | U | M | A | S | R | E | S | L | A |
|---|---|---|---|---|---|---|---|---|---|
| Postfix | Unary | Multiplicative | Additive | Shift | Relational | Equality | Strict Ops | Lazy Ops | Assignment |
var++ |
++var |
* / % |
+ - |
<< |
<= < >= > |
== != |
& |
&& |
= += -= *= /= ... |
Conditionals & Iteratives
Conditional Statements
This part of the page covers the if...else statement, the ternary operator, and the switch statement.
if, else, and ternary
There isn’t a significant amount of content beyond the basic if...else statement; something you may have missed however is the ternary operator. This is a shorthand for the if...else statement and looks like this:
// Our boolean condition
Boolean boolCond = false;
int value = 0;
// Your standard if-else
if (boolCond) {
value = valueIfTrue;
} else {
value = valueIfFalse;
}
// Using a ternary operator to achieve the exact same goal
value = (boolCond) ? (valueIfTrue) : (valueIfFalse);
You may be pleased to know that the ternary operator can be nested; this is basically only useful for code-golf, however.
Additionally, when explaining the semantics of an if...else statement, we can refer to the {} (curly brackets) as the construct. So we can say:
If the boolean expression,
boolCond, evaluates to true, then the body of the statement is executed, otherwise control passes to the next program statement after the construct.
switch
A switch statement is a way to simplify the if...else statement whilst also providing some additional control over how each case can be handled. First, the basic syntax:
switch (variable) {
case VALUE1: // Statements here if variable == VALUE1
break; // Do not continue executing!
case VALUE2: // Statements here if variable == VALUE2
break; // Do not continue executing!
default: // Statements here if neither case has been satisfied; however you can leave this blank.
}
The eagle-eyed amongst you will notice that each case is matched on an equality basis- not using equals() or compareTo(). Therefore, switch cases only work for the following primitives:
- int
- short
- byte
- char
Switch statements will also work on enumerated types (enums), Strings, and objects that wrap the corresponding primitives:
- Character
- Byte
- Short
- Integer
An example of a switch on a enum:
public class Main{
enum Colour{RED,GREEN,BLUE}
public static void main(String[] args) {
Colour c = Colour.RED;
switch (c){
case RED:
System.out.println("Colour is red");
break;
case BLUE:
System.out.println("Colour is blue");
case GREEN:
System.out.println("Colour is green");
default:
System.out.println("Default");
}
}
}
There are a few caveats to take away from this:
switchstatements are evaluated bottom to top- If a
casebranch matches thevariable, the expressions in thatcasewill be evaluated. - The
breakkeyword is optional. This means that theswitchstatement will continue running top to bottom otherwise, even after satisfying a case. Think about if you would like this behaviour! - The
defaultstatement is also optional; it is only evaluated if no cases match the variable expression.
Notably, if there is an absence of the break keyword and a specific case value has already matched the variable, the switch statement will continue running all the remaining statements inside each case without checking the value of the case.
For example, if the colour of our Colour enum above is BLUE, the output of the switch statement will be:
Colour is blue
Colour is green
Default
That is because, after c matches with the value BLUE, the switch statement continues executing all the remaining statements without checking the value GREEN. This can be avoided by using break.
switch vs if-else
In most cases, deciding between using a switch or if...else statement depends on readability and maintainability. However, for a larger number of cases (5 or more), a switch statement is generally faster. This is because the compiler creates a “jump table” based on each of the case values. Essentially, these are special byte codes that tell the Java Virtual Machine (JVM) which path of execution to take depending on the variable expression. Conversely, the JVM checks the boolean expressions in if-else statements one at a time, from top to bottom. This is why when there are many cases, a switch statement will run faster than equivalent logic coded if-else statements.
The compiler is able to do this because the values in a switch statement are always constant values at compile time, and can be compared easily with the variable expression as they are the same type. For if-else statements, they are boolean expressions that may depend on an arbitrary number of variables and conditions and the compiler cannot assume that the values will be constant.
Iterative statements
Whilst you are most likely familiar with while and for loops, it is important to understand the terminology that seperates the two. A while loop is unbounded repetition whilst a for loop is bounded; you cannot compile code which does not have a terminating condition.
Bounded repetition
Bounded repetition criteria
We use bounded repetition when we know all of the following:
- Where to start
- Where to end
- What iterative step to take at each repetition
The Java for statement is structured with for (initialisation; booleanCondition; iteration) { statement(s); }. Keep in mind that the sky is the limit when it comes to either of these three components; you do not always have to use i++ to iterate a list in forward direction.
Unbounded repetition
We can use this when we are unsure of how many times we want to repeat something. There is no Java police to enforce which repetition you use, but I would keep in mind how tidy your code is. Moreover, if you find yourself iterating in a while loop, make sure you understand the differences between postfix and prefix operators.
do...while statements
This is for when you want to execute the loop body before checking the expression; this means that the body will always be ran once. After the first initialisation, a do...while statement will only execute the code inside the do whilst the while condition evaluates to true. You may want to use this when generating random numbers, and then checking if these satisfy a condition… 🤖
Return of the break keyword
You can use the break keyword at any point inside a do...while, while, or for statement to halt looping within that scope. For example, this code would stop iterating once a certain limit has been reached:
for (int i = 1; i < 15; i++) {
if (i % 5 == 0)
break; // The code would stop looping at i = 5;
}
Arrays, Methods, Scope, and Recursion
Arrays
There are several key points to revise when it comes to answering questions about arrays:
- They are monomorphic lists- this means you can only store one type of data in it.
- Implementation wise, arrays are allocated on the heap in the JVM. These are contiguous blocks of memory, which means you can access elements by index. This is known as random access.
- You cannot create arrays of generic types. This means that you cannot create an array in Java if you do not yet know what type it stores- you can however store arrays of objects, as long as it is determined at compile-time. Therefore, in an exam, do not create a generic array. You are better off using a built-in collection such as an
ArrayList. - You cannot access elements of an array using pointer syntax, unlike in C. Not that anyone would attempt this when writing code in an exam, nor in practice for Java, but do not attempt it otherwise.
When arrays are declared (the name and type are defined), its value will be initialised to the special value null. This simply means that no value is assigned to the array yet, and Java knows that we want some contiguous block of memory to store some values, but this block of memory hasn’t been assigned yet.
To initialise an array, you can either use array syntax, or the new keyword. The new keyword essentially reserves a contiguous block of memory. Because arrays have fixed sizes once they are initialised, we also have to state/define the size of the array when we initialise it.
// Declaring an array of type int
int[] declaredArray;
// Also a valid declaration, where the [] goes after the variable name
int postfixSquareBracketsArray[];
// These are both set to null- we haven't actually reserved (allocated) any memory for them.
// This is how we allocate memory with the new keyword- notice how we've allocated in the same line.
int[] allocatedArray = new int[10]; // We allocated space for 10 integers. This size is not in bytes!
// This is one way to declare an array and populate it at the same time.
int[] populatedArray = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
Since the size of an array is fixed, if you want to resize an array, you’ll need to copy across your data from the first array into a new array variable, and then reassign the array.
The JVM (Java Virtual Machine) will use garbage collection to automagically delete the original array that is no longer in use- unlike languages like C where you must manually clean up the memory.
Example: Resizing an array
// Our first array of five integers
int[] smallArray = { 1, 2, 3, 4, 5};
// If we wanted to add two more integers, we wouldn't be able to do this.
smallArray[5] = 6; // This would fail, as the array is out of bounds! Remember that indexing begins at 0.
// We instead should create a new array of the size we want.
int[] largerArray = new int[7];
// We now need to copy the elements from the original array.
// Cast your mind back to bounded and unbounded repetition.
for (int i = 0; i < smallArray.length; i++) {
largerArray[i] = smallArray[i];
}
// We can now add new data to largerArray. You could continue by reassigning the variable names.
smallArray = largeArray; // This should replace the data pointed to by smallArray with the data in largeArray.
// Now, you can access the 6th and 7th elements of smallArray. Don't try this in C.
ICYMI, the length property, which is a part of all arrays in Java, was used to know when to stop iterating. There is a much neater and quicker way of copying across an array, found in the arraycopy method in the System class.
Multi-dimensional arrays
It is also possible to create multi-dimensional arrays; one must simply add another set of square brackets after the first set.
// 1st pair of square brackets refer to the "outer" array and the
// 2nd pair refers to the "inner" array.
int[][] twoDArray = new int[20][20];
// Populating a 2D array
int[][] twoDArrayTwo = {
{ 1, 2, 3 }, // The first element of the outer array
{ 4, 5, 6 }, // The second element of the outer array
{ 7, 8, 9 } // The third element of the outer array
};
// Assigning to a 2D array
twoDArrayTwo[0][0] = 1;
twoDArrayTwo[0][1] = 2;
twoDArrayTwo[0][2] = 3;
It is crucial to keep in mind that this is not a matrix. Although you can easily interpret this as a matrix, there is no table being constructed here - it is an array, where each element is also an array type. It would be much better to think of this as a list of vectors, which although would form a matrix, is not a special type like an array is.
Irregular array sizes
If you have an irregularly sized array, where the length of the rows are not equal to the length of the columns, you must create the outer array first and then create each of the inner arrays.
// This 2D-array has only initialised the outer array. The inner array is simply set to null.
int[][] arrayOfInts = new int[10][];
// This creates arrays of increasing size, for each of the 10 elements in the outer array.
for (int i = 0; i < arrayOfInts.length; i++) {
arrayOfInts[i] = new int[i];
}
Methods
The main method is a special method that is the entry point for a Java application.
All methods have a signature that defines the access privilege, the return type, the name, and its parameters.
| Component | Access privilege | Return type | Name | List of function parameters |
|---|---|---|---|---|
| Definition | Who can access this method from outside the class? | What type does this method return? | What should the name be? | Which arguments can be provided and used by the method? |
| Options | public, private, protected.Private means that no other classes can call this method from instances of this class, and protected means that only children of the class can call this function. |
Any object or primitive type, and void for no return. |
An ASCII string. | This can be left empty- if you provide arguments, they are in the form [type] nameOfArgument. If this is a list, they are comma separated. |
| Example | public static - this can be accessed from outside the class by the compiler, or any other classes. |
voidThe main function returns no type. |
mainA special compiler-recognised name that signifies the main entry point. |
(String[] args) The main method takes an array of strings as an argument. |
Function overloading
If you have more than one method of the same name, but different parameter lists, this is known as overloading. The compiler will recognise which method you’ve called based on the parameters you’ve given it.
// Two methods with the same name, and return type, but different parameters
// If the static keyword scares you, don't worry about it for now.
public static int integerMethod(int a) { return a; }
public static int integerMethod() { return 0; }
public static void main(String[] args) {
System.out.println("The parameter method: " + integerMethod(5)); // Will print "5";
System.out.println("The non-parameter method: " + integerMethod()); // Will print "0";
}
Scope
Scope refers to how long a variable is relevant for, and when it becomes relevant.
As an analogy, imagine if you just moved into a new house and there’s no furniture. If you tried to sit down on a specific chair, you wouldn’t be able to- there’s no chair in the room. You hop onto IKEA / Amazon, and order a chair, and it arrives in the room. The chair is now in scope. You can now sit on that chair in particular.
Let’s say that you decide not to put the chair away once you’re done. You’d rather keep it in the room you’re in, and you decide to do this for all the furniture you ever need- you never throw anything away. Your room, just like your computer memory, would soon fill up. Therefore, you realise you should throw some old chairs out- this is throwing the chair out of scope. You cannot sit on that chair anymore as you’ve just thrown it out!
In Java, we have the same analogy, roughly speaking. Our ‘room’ is defined between any pair of curly braces: { }. Once you reach the end of the curly braces, any variables in there go out of scope. Take a look at this code example:
public class Room {
// Creating a Door object. This will survive until the very last closing brace.
public Door doorObject;
{
// We are creating a chair in this scope.
Chair myChair = new Chair(); // Chair object enters scope. Remember, an object is an instance of a class.
doChairThings(myChair);
shut(doorObject); // The doorObject is still in scope, as we have not left its closing braces yet.
} // The myChair variable is no longer in scope once we leave these braces.
{
// We can create another chair here
Chair myChair = new Chair(); // This chair object is not the same as the previous one!
smash(myChair); // We won't be smashing the other chair, as the other one is out of scope- there is no 'other'.
}
doChairThings(myChair); // This will fail, as there's no more 'myChair' in scope.
slamDoor(doorObject); // This will work fine, as the doorObject is still in scope.
} // The doorObject also goes out of scope here.
Passing by value and passing by reference
When we pass variables to a method, sometimes these variables are passed by value - meaning the value of the variable is passed into the method (not the actual variable itself). Other times, the variables are passed by reference - the memory location of the variable is passed into the method.
public void randomMethod(int p) {...}
Passing by value
Only the 8 primitive types are passed by value - and this is always the case. This means that the value of the variable is cloned in memory and assigned to the corresponding parameter name of the method (e.g. p in the example above).
Any changes to the variable within the method’s scope do not affect the original variable - it only affects the cloned value. If you want to change the value of the original variable you need to assign a new value to the original variable, e.g. p++ which increments the value of p.
Passing by reference
Objects and arrays are passed by reference. Because objects can be very large and often contain many fields, the memory address of the variable is passed to a method (not cloned like primitives). This means changes made inside a method will directly induce changes in the original variable. Therefore, think carefully if you are attempting to copy a variable into a new one. (An example of this was when we copied an array previously into a larger one).
Recursion
A recursive function is any function that calls itself. There are common applications for this when calculating a Fibonacci number, or a factorial of a number. All recursive functions are made up of the following two components:
- Base case(s). These can be seen as values that are returned when an upper or lower limit(s) is reached. These cases can also be thought of as the terminating conditions for a recursive method (what condition must be fulfilled to stop the recursion).
- Recursive call(s). These are specific calls to the function again. Remember to use the
returnkeyword before a recursive call so that you eventually return the series of computations.
Example: factorial
f(x) = 1 if x = 0 ==> This is the base case
f(x) = x * f(x - 1) if x > 0 ==> This is the recursive call
If you are implementing this in any language, you can make the distinction between a base case and a recursive call by using a simple if...else statement or a switch statement. You must remember to return the result of either.
Object Oriented Programming
Before this, we have been discussing the von Neumann type architecture of programming (Imperative programming). Now we will move on to OOP. Here I will assume that you know most of the practical stuff like how to create a class and what constructors, fields/properties, and methods are. We will focus more on the “theoretical” part of it like what an object or class is formally and what are the motivations for OOP.
The 4 Pillars of OOP
Before we begin, I think it’ll be helpful to list out the 4 pillars of OOP. In this chapter, we will be going over encapsulation, while the last 3 will be discussed in further detail in the later few chapters/topics.
- Encapsulation: Bundling data and operations that can be performed on that data together - leads to data hiding. This is done by using the access modifiers (public, protected, private).
- Abstraction: Exposing essential features, while hiding irrelevant detail
- Inheritance: Creating new classes from existing ones, reducing programmer effort
- Polymorphism: Using objects that can take many forms (different from Generics) - allows us to invoke operations from derived classes while using a base class reference at run-time.
Imperative vs OOP
In procedural (or imperative) programming, we convert program specifications to method-based code. We use this in the C programming language, or Pascal. Data and operations on the data are separated.
In OOP, we take procedural programming and we add some more functionality. The main difference is that our data and operations on the data are bundled together in a structured called an Object! This lets us define individual objects with their own pre-set data very easily (is possible in imperative programming but its a hassle and the code is long).
Objects and Classes
Objects are made up of two main components: properties and methods.
The properties of an object store its state while the methods operate on this data and change its state.
When working with objects, the first thing to do is to create a blueprint of the object which we call the Class. The object itself will be a specific instance of this class.
A constructor is a special method that is meant to set-up the object according to some rules (you can think of it as giving the object some starting properties). If you don’t write a constructor, Java will create a default constructor - it does not set any values to the object. We can also overload constructors.
Why constructors?
The main reason we use constructors is to define a starting value for some (or all) of the properties of a certain object as it is created. This is usually important when these properties are necessary for the object to “make-sense”. For example, defining a Circle object without a radius doesn’t really make sense, so it would be good to define a constructor so that all Circle objects that are created will always have a radius. We will not need constructors when the particular class does not require these properties to function as it is meant to such as for static classes. In fact, it would not make sense for static classes to have a constructor because they are not meant to have instances.
// The class must be defined in a Circle.java file.
public class Circle {
double radius;
public Circle(double radius) { // Constructor
this.radius = radius;
}
public double area() {...}
public double circumference() {...}
}
Memory
Objects require a small amount of contiguous memory to store all their properties. To create new instances of a class we use the new keyword.
When we use the == on two variables, we are actually asking if the 2 variables are pointing to the same part of memory (in other words, whether the two variables are pointing to the same object). To check if objects have the same data/prop, you should know that we use the equals() method.
Encapsulation
You should be familiar with the private, public, and protected access modifiers.
- Public. Can be accessed outside the class
- Private. Can only be accessed from within the class
- Protected. Can only be accessed from within the class and by subclasses (children classes).
- Package private. Can only be accessed by other Objects in the same package. Java code is often arranged into packages.
Encapsulation is an idea that motivates data-hiding, where making data private and some methods public is known as data-hiding.
Encapsulation motivates users to use a class by its external interface (using public/protected methods).
The implementation of the class can be done in whatever way the programmer wants, but the overall external functionality of the class still remains the same. Meaning if its meant to be a bank ATM, the underlying code can be different (and up to the programmers) but its functionality remains the same and users interact with it the same way.
This also makes code more maintainable because if you change a particular way your class is implemented, such as changing a type from a Int to a Long, other programmers who use your class may have interacted with your public properties directly, instead of through a method. This would probably break their code - encapsulation avoids this.
Hence, encapsulation encourages us to use access modifiers they help to
- Restrict access to some data and methods (or to control the access of the data in our objects). Unnecessary detail is hidden.
- The implementation can change without ruining dependant applications. Maintains a good interface between programmers.
- Boundaries of responsibility are clear.
Interaction Interface (different from Java Interfaces)
We often refer to the public/protected methods that allow users to interact with our classes/objects as the interface that links users to your code. So accessor and mutator methods (getters and setters) which are very common in OOP are just some examples of methods that define the interface.
static and final
If we want a variable or method to be shared between instances of a class, we use the static keyword. This is where that particular variable or method belongs to the entire class - not to any single instance. To use static variables or methods, we do not need to instantiate an instance of a class (aka create an object).
We use static mainly when it doesn’t make sense to define a particular method/variable for specific instances.
The final keyword is used to prefix variables that we want to be constant. A good example would be ! We will not be able to change the value of variables prefixed with
final once they are assigned/instantiated with a value.
public static final double PI = 3.1415926543;
Inheritance, Abstract Classes, and Interfaces
Inheritance
Just like how we inherit certain traits from our parents, subclasses (children classes) inherit all methods and fields from their superclass (parent class) at first. After which, we can override or add features to the subclass. This is how we would do it in Java:
// Parent class
public class Food {
public void eat() {
System.out.println("This tastes amazing!");
}
}
// Child/subclass
public class Cake extends Food {}
In this case, Cake inherits the eat() method from the Food class even though we don’t specify it in the Cake class. That means we can call the eat() method from the Cake class like this:
public static main(String[] args) {
Cake chocolate = new Cake();
chocolate.eat(); // This is valid!
}
Because we haven’t specified anything in the Cake class yet the output we get is still:
This tastes amazing!
Now, if we want to override this method we can do something like this:
public class Cake extends Food {
@Override
public void eat() {
System.out.println("This cake tastes amazing!");
}
}
If we call the eat() method from the chocolate now we will get
This cake tastes amazing!
The @Override annotation
Before overriding the method in the Cake example, we write @Override, which is called a “method annotation”. This indicates to the compiler that method overriding is occurring. This is not required to compile, but it comes with the benefits of:
- Readability, as it is clear when method overriding is occurring
- Error checking, as the compiler produces a warning if overriding is not occurring, indicating the programmer is not doing what they are intending to
More information is available here, here, and here.
Why inheritance?
You probably already know this, but inheritance means that we can reduce repeated code. Another reason to use inheritance is so that run-time polymorphism is possible! We will discuss this in further detail below but essentially it allows us to define a general method for a superclass but do something specific to it depending on the eventual subclass that we have no knowledge of at compile time.
The super and this keyword
The this keyword is used to refer to the current instance of the class. In a similar way, the super keyword is used to refer to the superclass of the current instance.
super in the subclass constructor
The superclass’s constructor should be the first thing that you call when defining the subclass constructor - especially if there are parameters that the super constructor must take. Otherwise, Java will call the default (no argument) super constructor super() - and if it is meant to take parameters you will get a compile-time error.
If your subclass happens to have 2 constructors then one of them should call the other constructor with this() and the other should have super() in it.
Method overriding
From the example on the Cake class above, you have seen how we can override a method from a superclass. How about if we just want to extend the method but we don’t want to change anything in the super method? That’s right, we can call the super method in the subclass method:
// Cake class
public void eat() {
super.eat();
System.out.println("Wow I love cake!");
}
The output we get is:
This tastes amazing!
Wow I love cake!
But what if a certain superclass method is private? We won’t be able to access them from the subclass. However, this is where the protected keyword comes in handy, as subclasses can access the protected properties in the superclass. So lets say our Food class has a name field now and a setter to set the name.
public class Food {
...
private String name;
public void setName(String name) {
this.name = name;
}
public void getName() {
return this.name;
}
}
If we define name as private then the following code will give an error:
public class Cake extends Food {
...
@Override
public void eat() {
System.out.println("This " + super.name + " tastes amazing!");
}
}
We would have to use the getter method getName() to get the String value of the name field in Food. However, it is valid if we set private to protected.
Polymorphism
Static Polymorphism
Static polymorphism is essentially method overloading. It is polymorphism because the name of the method can represent different methods and how Java understands which method to call is based on the type and/or number of parameters!
It is called static because when we compile code, Java will be able to decide at compile-time which method will be called based on the parameters provided.
// Static polymorphism/Method overloading
public static void main(String[] args) {
hi();
hi("cake")
}
// Here we are overloading by number of arguments
public void hi() {
System.out.println("Hi!");
}
public void hi(String name) {
System.out.println("Hi " + name + "!");
}
Hi!
Hi cake!
Dynamic Polymorphism
On the other hand, Dynamic Polymorphism is run-time polymorphism - Java will determine what class to treat a specific object when the program is executed.
Lets look an example before elaborating. Adding on to our previous two classes Food and Cake, lets introduce two new classes Apple and Hungryboi:
public class Food {
public void eat() {
System.out.println("This tastes amazing!");
}
}
public class Cake extends Food {
@Override
public void eat() {
System.out.println("This cake tastes amazing!");
}
}
public class Apple extends Food {
@Override
public void eat() {
System.out.println("This apple tastes amazing!");
}
}
// Hungryboi digests a Food object x which calls x.eat()
public class Hungryboi {
public void digest(Food x) {
x.eat();
}
}
And now if we do this:
public static void main(String[] args) {
Hungryboi me = new Hungryboi();
Food somefood = new Food();
Food redApple = new Apple();
Food cheeseCake = new Cake();
Object random = new Cake();
// Remember that the digest method calls the eat method
// in the Food, Apple, and Cake class
me.digest(somefood);
me.digest(redApple);
me.digest(cheeseCake);
// Print out the results of the instanceof operator
System.out.println(random instanceof Food);
System.out.println(random instanceof Cake);
System.out.println(random instanceof Apple);
System.out.println(random instanceof Hungryboi);
System.out.println(cheeseCake instanceof Apple);
System.out.println(cheeseCake instanceof Food);
}
Our output is (you can check it yourself by copying the code):
This tastes amazing!
This apple tastes amazing!
This cake tastes amazing!
true
true
false
false
false
true
The reason why line 2 and line 3 show the output for the Apple and Cake class respectively is because even though they are declared as a Food type, Java resolves their types at run-time. Java is able to tell that one is the Apple subclass, and the other is the Cake subclass, and it calls the appropriate subclass methods.
This only works because the Food class also has the eat() method defined. If we wanted to use a method that is only defined in the Cake class, then we would have to cast cheeseCake to a Cake.
public class Cake extends Food {
@Override
public void eat() {
System.out.println("This cake tastes amazing!");
}
public void admire() {
System.out.println("This cake looks amazing!")
}
}
public static void main(String[] args) {
Food cheeseCake = new Cake();
cheeseCake.eat();
cheeseCake.admire(); // Does not work will produce compile-time error
// The error message will probably be:
// "The method admire() is undefined for the type Food"
((Cake) cheeseCake).admire(); // Works
}
Something to note:
If you’re on Java SE 15 or newer and try this line of code below - you will get an error.
System.out.println(cheeseCake instanceof Hungryboi)
That’s because at compile-time, Java knows casting fails so instanceof comparison will fail as well and it tries to warn you to save you time. Click here for a better explanation.
Quick Recap
Static vs Dynamic Polymorphism
Static polymorphism has to deal with polymorphism at compile-time. This usually refers to method overloading where a single method name can refer to a range of methods that differ by either the type of their parameters or the number of parameters they have. The Java compiler identifies this at compile-time and it is converted into byte-code for the JVM (Java Virtual Machine) to interpret, which then converts the byte-code to the native machine code and executes the program.
Dynamic polymorphism refers to polymorphism at run-time, this is because the JVM decides which method is to be called only at run-time. At compile-time, calling a method is considered by its reference type (e.g. Food somefood is of type food where somefood is the reference). At run-time, the specific method that is called will be decided by the type of the object that the reference is pointing to/holding (e.g. Food somefood = new Cake(), so the methods that will be called will be from the Cake class). Here we say that it is resolved at run-time because the compiler does not know if the method has been overridden or not (N. Joshi, 2019).
Method overloading vs overriding
Two methods are overloaded when they have the same name but different types/number of arguments (essentially their list of arguments must look different). Other than that, overloaded methods can return different types, do different things or throw different exceptions. Method overloading can happen in the same class or in subclasses.
A method from a subclass overrides a method from a superclass when it has the same name and same type and number of arguments. There are a set of rules that the subclass method must abide to such as having the same return type, must have the same or less restrictive access modifier, and must not throw new or broader checked exceptions. Method overriding can only happen to inherited methods, which imply that it can only happen between subclasses and their superclass(es).
Check out this article by Naresh Joshi for a more in-depth explanation.
Abstract Classes
If we recall, the motivation behind inheritance is to reduce repeated code and to allow for run-time polymorphism. By now you should realise that each subclass becomes more specific than its superclass, and eventually superclasses become so general that they seem abstract. We can call these general classes abstract classes.
Properties of abstract classes
Firstly, abstract classes cannot be instantiated. The reason is that they are meant to capture common properties and behaviours at an abstract level and are meant to be extended (or inherited from) to make a subclass that is more specific. Therefore, there should not be a need to instantiate abstract classes.
In fact, it would not make sense to instantiate/define and instance of an abstract class because of abstract methods. These are methods that would not make sense for the abstract class to define but makes sense for its subclasses to define. Abstract classes can contain a mix of abstract methods and concrete methods.
Lets give an example:
Suppose that we want define an abstract Food class for an online supermarket. (I tried to come up with a better example… :pensive: )
public abstract class Food {
// Protein, carbs, and fats in grams
private double protein;
private double carbs;
private double fats;
// Return total amount of calories in a Food (Concrete method)
public double calories() {
return protein x 4.0 + carbs x 4.0 + fats x 9.0;
}
// Abstract methods
public abstract String description();
public abstract double price();
}
Here we have defined the calories method for the abstract Food class. This is a concrete method because all kinds of food will always have a certain amount of protein, carbohyrdates, and fat which will always be 4,4, and 9 calories per gram. Therefore, it makes sense to define a concrete method for all kinds of Food (Remember that any subclasses will inherit this method from Food).
Next, there are the abstract methods for description and price. Since every kind of ingredient/type of food that will be sold at the supermarket is going to be different it doesn’t make sense to define a concrete method for all Food.
However, we know that we want to have a description and price for each item and hence we define these 2 abstract methods for all kinds of Food. This makes it compulsory for subclasses to have a specific and concrete definition of these abstract methods. This is useful when using Generics because any class that extends the abstract Food class is guaranteed to have a definition for description and price.
Just in case there’s confusion: Inheriting from an abstract class is the same as any normal classes.
public class NewYorkCheeseCake extends Food {...}
Interfaces
Now that you have an idea of what an abstract class is, what its properties are, and what it is kind of used for, interfaces become really easy to understand. Just think of interfaces as the most abstract class in a hierarchy of classes. This is where there are no concrete methods at all and all methods are abstract.
Here is how we define an interface:
public interface Hi {...}
and this is how we implement an interface (I sincerely apologise for my lack of creativity :sob:)
public class Hi2 implements Hi {...}
Properties of interfaces
As mentioned earlier, interfaces have no concrete methods and all methods are abstract.
Just like abstract classes, interfaces cannot be instantiated.
Additionally, interfaces can only contain:
- Fields which are public static final and if not specified are defaulted to this
- Methods which are not defined/implemented. (They must be left “empty” like abstract methods but they shouldn’t be declared with the keyword abstract!)
public interface Hi {
int var1 = 1;
public static final int var2 = 2;
public void method1();
public int method2(int a, int b);
public boolean method3(int a, Test b);
...
}
Multiple inheritance
While Java doesn’t allow multiple inheritance (meaning that we can’t extend from two different superclasses - only 1 superclass per subclass!), Java allows you to implement multiple inheritance because interfaces just require a class that implements it to define a particular method - there is no “inheritance” of a particular definition of a method.
Why interfaces?
This all seems pretty useless doesn’t it? If we aren’t defining anything concrete, why bother with interfaces at all? (That’s what I thought too until I was enlightened 🤯).
We bother because interfaces are used to encapsulate a small subset of functionality/a property.
What does that mean?
Interfaces allow us to give concrete classes a certain functionality/property that perhaps isn’t appropriate to define in a subclass-superclass class hierarchy. Lets give an example to explain:
Suppose we have the class hierarchy as shown below, where Animal, Striped, and Plain are abstract classes and the last level of classes are concrete.
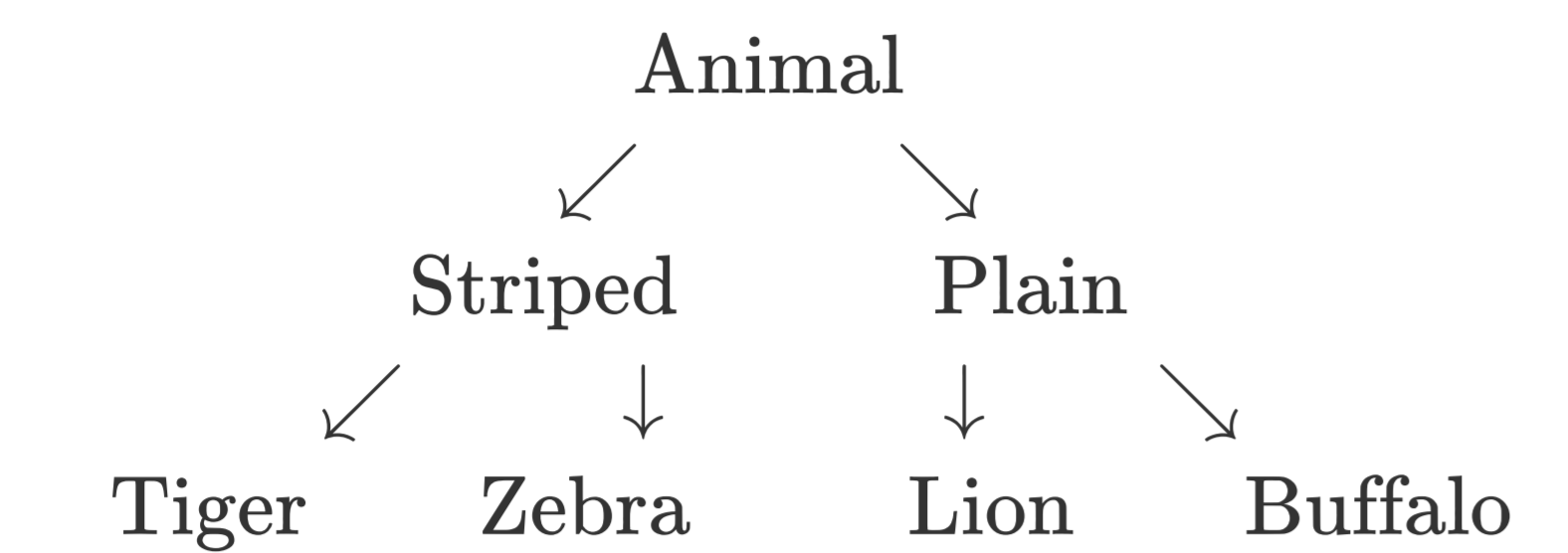
Suppose now that we want to be able to compare the number of stripes that an animal has. So that we can easily do something like
Tiger bob = new Tiger();
Zebra tom = new Zebra();
bob.compare(tom);
bob has more stripes than tom
To do this we can implement the Comparable interface (Its in Java.util) in the Striped class and define the compareTo() method for the Striped class.
public abstract Striped extends Animal implements Comparable<Striped> {
private Integer stripes;
public String nickname;
public Integer getNoOfStripes() {
return this.stripes;
}
// Custom compareTo method
@Override
public int compareTo(Striped animal) {
int comp = this.stripes.compare(animal.getNoOfStripes());
if (comp == -1)
System.out.println(this.nickname + " has more stripes than " + animal.nickname);
else if (comp == 0)
System.out.println("They have the same number of stripes");
else
System.out.println(this.nickname + " has fewer stripes than " + animal.nickname);
return comp;
}
}
Now any Animal that is Striped as well can be compared with each other based on the number of stripes that they have. This may allow additional functionality such as sorting striped animals by the number of stripes they have.
Error Handling and Exceptions
The original delivery of this content loosely introduced what an exception was, then demonstrated the try-catch statement, before explaining more about exceptions, and then demonstrating the try-catch-finally statement, before delivering more theory. As a result, I have opted to deliver as much theory as possible at the beginning, before diving into any code examples. If you are looking for the try-catch statement and its variant, then this can be found at the bottom of the page.
What are exceptions?
According to official Oracle documentation, an exception is an event, which occurs during the execution of a program, that disrupts the normal flow of the program’s instructions.
Technically speaking, it is useful to know how an exception can arise and how the JVM creates and handles these when your code is running:
- An error occurs in your method at run-time (for example, you try to access the 10th index of a 9-wide array).
- The method creates an exception object and hands this off to the runtime system. This object contains important information:
- The type of error
- The state of the program when the error occurred
- Creating an exception object and handing it to the runtime system is known as throwing an exception.
This is an alternative to traditional error-handling techniques, such as performing range-checks (with an if...else statement) every time you want to access an element from an array. As your code grows and you create more classes and objects, exceptions are a much more elegant way of stopping any run-time errors from occuring.
You will have noticed that these are exception objects, which means they are instances of classes. There are many different Java exception classes from a range of packages, and as you will see shortly, you can choose which type of exception you want to handle based on the specific object the exception takes the form of.
Exception classes vs. Error classes
In Java, the Throwable class is a superclass of both the Exception and the Error classes. There is an important distinction to make between the two (Java specification):
- An
Erroris a subclass ofThrowablethat indicates a serious problem that a reasonable application should not try to catch. - The
Exceptionclass and its subclasses are a form ofThrowablethat indicates conditions that a resonable application might want to catch.
How do you use exceptions? (The try-catch statement)
In order to make your code throw exceptions, you must use a try-catch statement. They take the following form:
try {
// Code that could generate an exception
object.somethingPossiblyNotOkay();
} catch (BadExceptionClass e) {
// Code to handle the event you come across a BadExceptionClass specifically.
} catch (AnotherVeryBadExceptionClass e) {
// Code to handle the event you come across an AnotherVeryBadExceptionClass specifically.
} finally { // This is an optional block.
// Code that will ALWAYS be executed at the end.
// This is executed even if there are return statements in the previous code blocks.
// You may want to use this to close / tidy up any resources.
}
How does this work?
- The code in the
tryblock is executed, and the JVM will see if an exception is thrown. - If an exception of class
BadExceptionClassis thrown, then the code in the firstcatchblock will be executed. This works vice-versa for any specific exceptions that you catch with acatchblock- similar to aswitchstatement. - You can query the specific exception with the use of a variable- in this instance, you could use the
esymbol to perform operations on the exception that was caught. - If an optional
finallyblock exists, the code in this block will always be executed. This is ideally used to tidy up any residual resources, such asScannerobjects.
If you code doesn’t cause any runtime errors, then none of the code in the catch blocks will be executed. Moreover, if a non-matching exception is thrown, the JVM will resort to any default error handling.
Exceptions and inheritance
It is important to note that since exceptions are based on classes, the order in which a superclass exception and a subclass exception is caught has significant implications on your code. Specifically, if the first catch block is a superclass of another catch block, then the subclass catch block will never be executed
Checked and unchecked exceptions
Now that we are familiar with try-catch statements, we can delve into the difference between checked and unchecked exceptions, and how they must be handled.
Checked exceptions (throws)
A checked exception is any exception that must be checked at compile-time. For example, you may want to use the BufferedReader class to open a file and read the first line, but there are two possible exceptions that could be thrown:
- The file does not exist, and would throw a
FileNotFoundexception. - There could be an error when reading a line, which would throw an
IOExceptionexception.
Both of these exceptions are checked and must be ‘caught or declared to be thrown’. Here is an example of code that does not compile due to not checking these exceptions:
someMethod() {
BufferedReader read = new BufferedReader(new FileReader("maybeFile.txt"));
String line;
while ((line = read.readLine()) != null) {
System.out.println("Found line: " + line);
}
}
You have two options when it comes to handling checked errors:
- Surround the two statements in a try-catch block
- Re-throw the exception using the
throwskeyword
It is almost always better to use the latter option, unless you have a penchant for adding many try-catch statements into your code.
Using throws
In the example above, the FileNotFound exception is a subclass of the IOException exception. If you cast (🥁) your mind back to the superclass and subclass scenario, this means we only need to catch the IOException, and could maybe query the exception object specifically. The throws keyword can be added in the method signature and will handle this for us; we can therefore fix the above code as follows:
someCompilableMethod() throws IOException {
BufferedReader read = new BufferedReader(new FileReader("maybeFile.txt"));
String line;
while ((line = read.readLine()) != null) {
System.out.println("Found line: " + line);
}
}
Unchecked exceptions
These are any exceptions that do not need to be checked at compile time ‘if they can be thrown by the execution of the method or the constructor and propogate outside the method or constructor boundary’. In English, this means that exceptions that are subclasses of Error and RuntimeException- for example, trying to divide by 0 will throw the ArithmeticException. It does not make sense to have to catch this at compile time, but you can choose to check and handle it in a graceful manner. A final way to decide between which type of exception to use is this (from the Java documents):
“If a client can reasonably be expected to recover from an exception, make it a checked exception. If a client cannot do anything to recover from the exception, make it an unchecked exception”.
Writing your own exceptions
As stated before, any Exception is just a class that extends the Exception class. Therefore, if you are writing your own exceptions, you should choose the most specific exception that encapsulates your Exception, and then extend this.
If however you are extending an unchecked exception, then you should extend a RuntimeException. (Use the criteria above to decide which exception to extend). It is typical for you to add messages and perhaps chain other exceptions together in any custom exceptions- this can be used to add detail to previous exceptions.
It is at this point that we can revert to using if...else statements to decide when to throw (not throws) our new exception- for example, imagine if you wanted to use a method to raise a number to a certain power, as long as this index was positive:
int index = -1;
if (index > 0) {
raisePower(5, index);
} else {
// This may or may not be an existing exception- pretend that we've just created it now, and that it extends from an Exception that also takes a debug message to be printed.
throw new NegativeExponentException("You asked for a negative exponent: " + index);
}
Chaining exceptions
There are four constructors for most Exception classes:
- Default constructor, no parameters
- Constructor which allows for an error String
- Two constructors which have space for another
Throwableclass, which allows you to chain exceptions together.
You can use the built-in Throwable member methods to find out more about the exception, which will allow you to chain together information and/or exceptions specifically based on the cause of the run-time error. This page contains the documentation for the Throwable class. You can use that page to check through the methods that you think are relevant to your code in particular, rather than them all being listed here.
Generics and the Java Class Library
By this point, you’re most likely familiar with how to create your own classes, how to create subclasses, and how you can use abstract classes and interfaces to broadly define behaviour.
Why Generics
Using generics in your code makes it safer and more reusable, notably it allows
- stronger type checking at compile-time.
- elimination of type casts
- implementation of generic algorithms tailored to different types.
The key implication of this is that you are less likely to encounter run-time errors because you can you catch type related errors at compile-time.
Take the following example, where we load a Stack which one type of object, and try to read this object as another type:
// Creating a new stack, it simply holds data of type 'Object'
Stack stack = new Stack();
// String is a subclass of Object and this operation passses
stack.push("hello");
// We are attempting to cast the String object to an Integer Object
// this isn't possible at runtime.
Integer n = (Integer) stack.pop();
Note how when we created the Stack object, we didn’t specify what type it would hold- this was defined in the Stack class itself. This meant there wasn’t necessarily a restriction on whether we decided to store a String or an Integer first.
Imagine if we had done the following- we create a new subclass of Stack that will only store String objects in an array, so we cannot store any other type. Our code would look like this:
// We create a new type of Stack that only stores Strings
StringStack stringStack = new StringStack();
// We can push a String onto the StringStack as the class specifies this type.
stringStack.push("hello");
// StringStack specifically returns a String from the top of the stack
// this cast would fail at compile time, ideally, as the compiler should
// know that this is a mismatched type.
Integer n = (Integer) stringStack.pop();
It would be incredibly tedious to have to create a new type of Stack class every time we wanted a different data type to be stored. Luckily, Java enables this behaviour through the use of generics- our code could look roughly like this:
Stack<String> stringStack = new Stack<String>();
Stack<Integer> intStack = new Stack<Integer>();
stringStack.push("hello"); // This passes
intStack.push(5); // This also passes
intStack.pop(); // This returns an integer by default
stringStack.pop() // This returns a string by default
Thinking of Generics
There are two ways I like to think of generics in Java:
- A screwdriver which has swappable heads, and when you create an object, it’s like choosing the correct head for the screw.
- Defining a generic in a class is like creating a placeholder which you will fill in later when you instantiate the object.
It therefore goes without saying that you cannot create an object of a class which uses generics without providing which type you’d like to use! In accordance with the analogy above, it would be akin to not putting a head on the screwdriver.
Implementing Generics
Now that you’re convinced of their usefulness, here’s how you would create a class that utilises generics (the example we’ll go for is a Box that stores only one type): $\;$
// Within this class, we will refer to this generic object as 'E'. This
// can be used like a type - imagine it as a synonym for whatever type
// you're going to put into the box.'E' is decided on by Java conventions
// - it is not enforced by the compiler
public class GenericBox<E> {
private E item; // A private member of type E
// We take an element 'e' of type E, and set the item field to this.
public GenericBox(E e) {
this.item = e;
}
public void set(E e) {
this.item = e;
}
public E get() {
return this.item; // item has type E and hence can be returned.
}
}
Now, when we instantiate the object, we can decide what types to fill it with at runtime:
GenericBox<String> stringBox = new GenericBox<String>("A string in a box");
GenericBox<Integer> intBox = new GenericBox<Integer>(42);
stringBox.get(); // Will return "A string in a box" in a String object.
intBox.get(); // Will return 42 in an integer object.
You can use multiple generics at the same time- just put the types in a comma-separated list within the diamond brackets:
public class TwoTypes<E, F, G> { ... }
You can also enforce a specific restriction for each type - what if you wanted to only store objects that can be compared to one another?
public class ComparedObjectsOnly<E extends Comparable<E>> { ... }
In this example, the Comparable class constraint is extended by all objects that can be compared to one another using -1, 0, or 1. This also means you can store your own kinds of comparable objects as a generic - it isn’t limited to build-in classes such as String or Integer. It is important to note that you cannot use primitives with generics.
As mentioned earlier, there is a convention that exists when deciding which symbols to use for generics:
Efor ElementKfor KeyNfor NumberTfor TypeVfor Value
Some of these will make more sense when you cast your mind back to CS126, and where each of those ideas are used for various data structures.
Generic Methods
When defining some methods, it might be useful to write generic method that only operate of particular types. For example, lets say you have a compare method as shown below:
public static boolean compare(Pair p1, Pair p2) {
return p1.getKey().equals(p2.getKey()) &&
p2.getValue().equals(p2.getValue());
}
With this definition the following code will be valid even though the Pair object might contain types that do not match:
Pair<Integer, String> t1 = new Pair<>(3,"bleh");
Pair<String, String> t2 = new Pair<>("hi","bye");
compare(t1,t2); // Valid even though it doesn't make sense!
Hence, to specify the generic types that the compare method will take as parameters, we can define the compare method like this:
public static <K,V> boolean compare(Pair<K,V> p1, Pair<K,V> p2) {
// compare...
}
Now when we try to compare Pair objects that contain mismatched types, a compile-time error will appear.
Do note that we won’t have to specify the generics in the method if the generics that you want to refer to in the parameters of the method are already defined at the class-level, like it is in the first line of the GenericBox class defined above.
The Java Class Library
The original lecture for this content spent some time going over the Java Class Library I felt it would be improper to include lengthy descriptions here, as there is no way to really define what is useful or not. It is up to you to search through the documentation and decide what you find interesting - for a first start, check out the util documentation and try and find some classes you recognise, such as Stack or Iterator.
Going through the documentation in this safe space means you can pick up valuable skills on how to read a specification when your IDE does not have any suggestions.
Concluding notes from the author
This abruptly brings us to the end of the modular CS118 revision notes! 🎉🎉 Thank you to everyone who submitted content, and remember to contact someone (or submit a pull request) if you spot any errors or would like to make a contribution for any modules, listed or otherwise. I hope by this point, there will be some answers to the questions posed on the CS118 landing page.
Thank you once again for this community effort.